

The Hardest Document Extraction Problem in Insurance

At FurtherAI, we build AI agents for commercial insurance. A huge part of what they do is process documents - messy, inconsistent, high-stakes documents.
One of the hardest - loss runs. These are claim history reports that insurers use to price policies. Think of them as the "credit report" equivalent for a business's insurance risk. They list every claim filed over the past few years - what happened, how much it cost, what's still outstanding.
The problem is that these documents come from hundreds of different sources, and no two look alike. Some are clean single-page tables. Others span 200+ pages with data buried across sections, each formatted differently. Around 30 fields per claim need to be extracted accurately into a structured format.
If you've ever tried to extract structured data from PDFs, invoices, medical records, or legal filings, the challenges here will feel familiar: semi-structured layouts, implicit hierarchies, meaning that depends on position and context rather than just text.
We built a self-correcting extraction system that went from 80% to 95% row count accuracy -not by improving the extraction model, but by giving an agent the tools to check and fix its own output. This post digs into how we built it, and what we learned along the way.
In this post:
- Why loss runs break every extraction pipeline we've seen
- From curated prompts to self-correcting agents — and why the leap matters
- A self-correction loop where the agent debugs its own output
- The 10-line validation function that outperformed weeks of prompt engineering
Why This Is Hard
One document we worked with had four separate tables spread across five pages, all describing the same 10 claims — policy info in one table, dates in another, descriptions in a third, financials in a fourth. The same claim number appears in each, but with different fields populated. Building a complete record means figuring out which rows to join across tables, which is a reasoning task that goes well beyond reading text off a page.
And that turned out to be one of the easier ones. As we worked through more documents, new patterns kept surfacing. A 180-page document where the policy number shows up once as a section header on page 5, then ~100 claims follow with no repetition — miss the header, and every claim in the section gets the wrong metadata. Summary rows that look identical to claim rows, same columns, same financial data, except they're totals, not individual claims — one document inflated our claim count by 15% because of these. Blank cells that don't mean "empty" but "same as the row above" — a carrier puts the claim number on the first row of a group, then leaves it blank for the next three coverage lines under the same claim. Claims with $0 across every financial field that might be closed without payment, or might be data entry placeholders, depending on the carrier.
Each of these patterns broke something in our pipeline at some point. The OCR was never the bottleneck — the real challenge is that every carrier has their own conventions, and the only way to handle them is to reason about what the document is actually trying to communicate.
From Agentic Extraction to Self-Correction
Our first version was simple: one API call to a commercial extraction API with a JSON schema. It worked surprisingly well on clean documents — but on the messy ones, we kept finding claims that had silently vanished. A document would clearly list 45 claims, and we'd get back 30.
Stage 1: Agentic extraction
The obvious next step was to put an LLM agent in charge. We gave it a curated prompt describing loss run structure, a tool to call the extraction API with optional page ranges, and a tool to visually inspect specific pages of the PDF. The agent could decide its own extraction strategy — extract everything at once, chunk by page range, or visually verify suspicious sections.
This helped immediately. The system was able to reason about document structure — for example, recognizing when a section continued onto the next page or when a header applied to the claims that followed. But after that initial improvement, further gains were harder to sustain. We kept refining the prompt, adding guidance for layouts we had already seen, and incorporating new edge cases as they surfaced. Some of those changes improved performance on familiar documents without generalizing to the next one. The more we relied on prompt design alone, the clearer it became that we were improving at the margins rather than addressing the underlying source of error.
Stage 2: The self-correcting loop
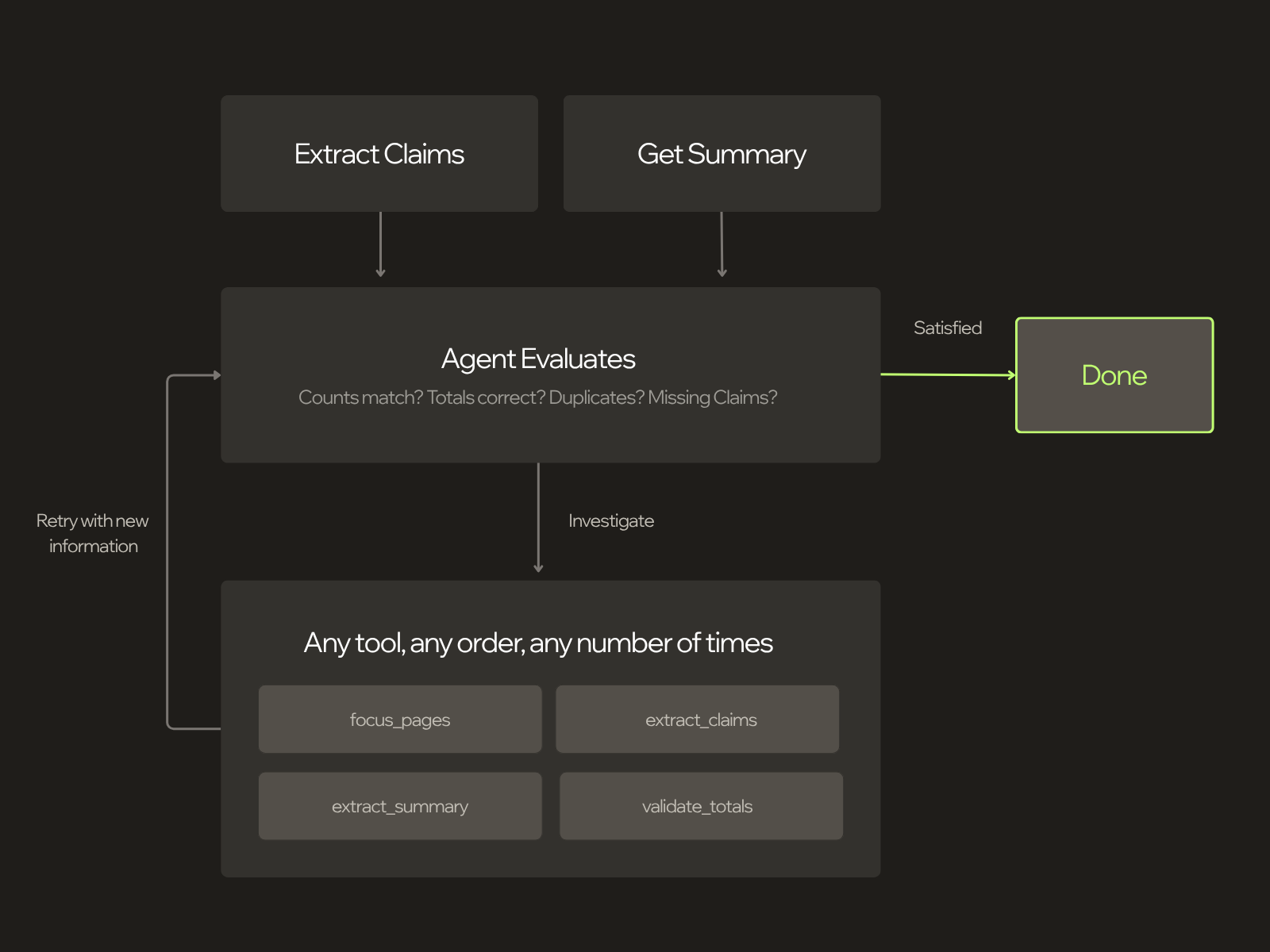
The key shift was to stop treating this primarily as a prompt-tuning problem and instead treat it as a feedback problem. Instead of a curated prompt that prescribed an extraction strategy, we wrote a non-prescriptive skill: a description of the task, the document domain, and what a correct output looks like, including verifiable validation criteria. We then gave the agent a validation tool and allowed it to iterate.
This changed the role of the agent. Its job was no longer to follow a preferred extraction strategy, but to produce a complete, validated result using the evidence available in the document. It calls the extraction service, checks the output against the document's own summary totals, and if something does not add up, it investigates. It can zoom into specific pages, re-extract sections it considers suspicious, and continue until the numbers match.
In practice, the agent has three tools:
async def extract_claims(ctx, page_start=None, page_end=None) -> str:
"""Extract claims from the document. Supports optional page ranges
for iterative re-extraction of specific sections."""
async def focus_pages(ctx, pages: list[int]) -> ToolReturn:
"""Returns high-resolution PDF chunks of specific pages
for detailed visual inspection."""
async def validate_totals(ctx, claims: list[ClaimRecord]) -> str:
"""Validates extracted claims against document totals.
Checks financial totals AND claim count."""
For shorter documents, we feed the entire PDF into the agent's context. For longer ones (100+ pages), that would blow the context window when the agent starts reasoning. So we give it the first and last few pages — enough to see the structure, headers, and summary totals — plus tools to navigate the rest. The agent decides its own strategy from there: which pages to inspect, how to chunk the extraction, when to re-examine a section.
Watching the agent think
Here's what this actually looks like. A 5-page loss run, 35 claims across three coverage periods. Transcript edited for clarity:
The extraction backend returned 38 claims when the document clearly stated 35. Without the self-correction loop, those 3 extra claims — duplicates created at section boundaries — would have silently made it into the final output. Instead, the agent caught the discrepancy, investigated each section visually, identified the duplicates, corrected a claim number typo it spotted along the way, and re-validated until every count and every dollar matched. No human encoded this failure mode. We didn't write a rule for "duplicate claims at section boundaries" — we gave the agent a validation tool and a clear success criterion, and it figured out the rest. This is the key insight: rather than anticipating every way extraction can fail, you give the model the tools to verify its own output and the intelligence already baked into frontier models does the debugging for you. As models get better, this approach gets better automatically.
The system prompt philosophy
This is the core difference between stage 1 and stage 2. The agentic extraction prompt prescribed a strategy — here's how loss runs work, here's how to chunk, here's how to handle multi-table layouts. The self-correcting loop prompt describes what correct looks like and lets the agent work backward from there:
Use your tools in whatever order is most appropriate for the document. You are free to explore the document, inspect suspicious sections, and decide which steps are necessary to reach a complete result.
Do not stop until the extraction is complete and validation is satisfied.
If validation reveals a mismatch, continue investigating. Depending on the document, useful next steps may include:
- Re-examining pages where claims may be missing
- Re-running extraction on specific page ranges that need closer review
- Checking whether claim information is distributed across multiple tables or sections
- Inspecting headers, subtotals, and section transitions that may affect claim grouping
A complete extraction is more important than a fast but partial result.
Results
We evaluated these approaches on a comprehensive dataset drawn from some of the most difficult real-world loss run cases we encounter in client workflows. Scores are averaged across ~30 fields and grouped into the categories below:
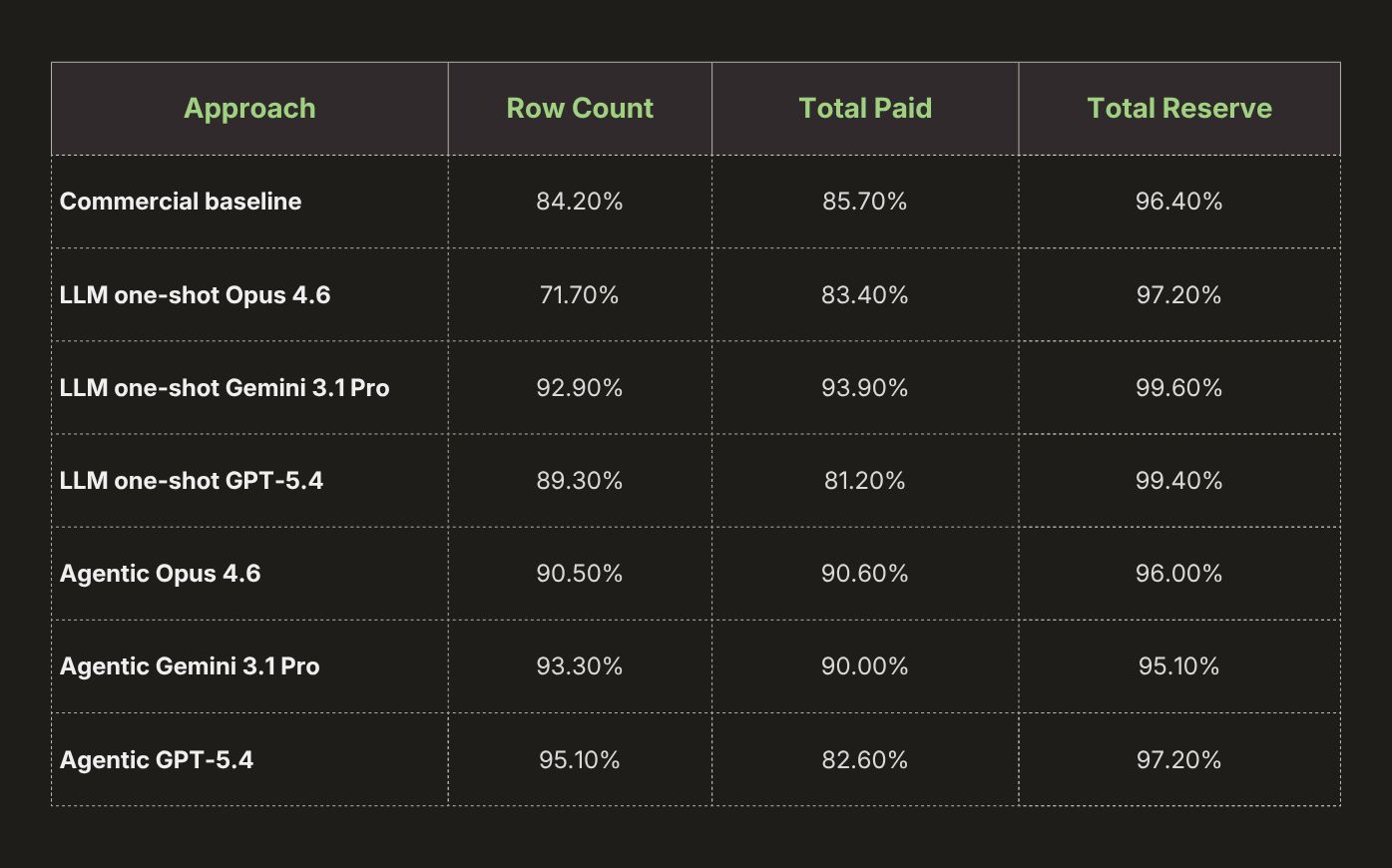
Row count and financial totals should be read together. Because the totals metrics are computed only over extracted rows, they isolate value accuracy conditional on the claims the system found. This means a system can score well on totals while still missing claims, so strong totals accuracy alone should not be taken as evidence of extraction that is accurate and useful to the user.
Within this framing, the agentic GPT-5.4 result appears strongest overall, primarily because it achieves the best row-count accuracy in the comparison, and row count is a particularly informative metric for practical extraction quality.
These results are most useful when read as a progression rather than as a single ranking. The move from a one-shot extraction call to agentic extraction produced the first substantial improvement, which suggests that the main difficulty in loss runs is not OCR alone, but reasoning about document structure across pages, sections, and tables. Although the gains vary by model and backend, the overall pattern is consistent: once the system can inspect the document selectively and choose its own extraction strategy, performance improves materially.
The larger shift comes with the self-correcting loop. Agentic extraction improves the quality of the initial pass, but validation changes the behavior of the system after that pass by giving it a mechanism for detecting inconsistencies and revisiting the document when necessary. This reduces silent failures and makes the overall extraction process more reliable. The financial results follow the same pattern. In this setting, errors are often less about reading individual values than about missing claims or grouping them incorrectly, so improvements in claim coverage translate directly into better downstream financial accuracy.
Measuring these systems was nontrivial. Loss runs vary widely in structure, often omit claim identifiers on some rows, and frequently spread the same claim across multiple sections or tables, so exact string matching was not enough to evaluate extraction quality meaningfully. Where possible, we aligned claims by normalized claim number; when that was not possible, we used an optimal assignment over fields such as coverage, dates, and descriptions to match ambiguous records and avoid downstream misalignment from missing or shifted rows. We also scored outputs leniently when they preserved the right information in a different surface form, since abbreviations, date formats, and related field conventions often vary across carriers. There is much more to say here — from claim alignment to semantic scoring to the broader tradeoffs in evaluating messy real-world documents — but the main point is that reliable measurement required a more careful evaluation framework than exact-match metrics alone.
Conclusion
The winning formula has four parts:
- Agentic loops. Don't settle for a single extraction pass. Give the system the ability to try again, from a different angle, with more information — as many times as it takes.
- Validation tools. The biggest gains came from giving the agent a way to check its own work against the document, detect mismatches, and keep going until the evidence lines up.
- Success criteria over rigid procedures. The more robust approach was to define what a correct extraction must satisfy, rather than prescribe brittle steps for every layout variation. That proved more resilient across carriers, document formats, and extraction backends, and it improves naturally as underlying models improve.
- Rigorous evals. Reliable measurement is what makes iteration trustworthy. Without it, it is too easy to mistake superficial agreement for real progress.
With that combination, we are achieving very high accuracy on a critical workload where errors directly affect underwriting decisions. We are not done — there are clear paths to improve financial field categorization, metadata coverage, and handling of the most unusual document formats. But the accuracy we are seeing today, on a task that can involve thousands of claims across hundreds of pages, is on par with or better than what manual human review typically achieves — and it takes seconds instead of hours.
This is one of many problems we're working on at FurtherAI. Insurance documents are interesting - the edge cases never stop, and the best solutions tend to be surprisingly simple once you find them. A 10-line validation function turned out to be worth more than weeks of prompt engineering. If that kind of work sounds fun to you, we're hiring.






.svg)






